

Understanding Self-Attention, Multi-Head Attention, Cross-Attention, and Causal-Attention in LLMs
Part two

Weight Matrices
In part one we introduced the self-attention sample sentence, kindly take a read on that if you have not already done reading.
In the context of self-attention, the query, key, and value sequences (Q, K, V) are generated by linearly transforming the input sequences (embeddings) using learnable weight matrices,
Let's break this down step by step.
First, you start with the input sequence, which is a matrix of embedded vectors. If you have a sentence or sequence of tokens, each token is represented as an embedding vector. Suppose the input sequence is X, which has dimensions
where:
N is the number of tokens in the input sequence.
d{model} is the dimensionality of each token's embedding (e.g., 512 or 768).
So, X is essentially a matrix where each row represents an embedded token.
Step 2: Linear Transformations (Learnable Weights)
In self-attention, you need to project the input X into three different spaces to compute the query (Q), key (K), and value (V) matrices. This is done using three sets of learnable weight matrices, which are randomly initialized and updated during training. These matrices have the following dimensions:
Where d_{k} \; d_{q} \; d_{v} are usually the same and are often set to d{model} (though sometimes they can be smaller for computational efficiency).
\(W_{k} \in R^{{d{model} \;* \;d{k}}}\)The key weight
\(W_{q} \in R^{{d{model} \;* \;d{q}}}\)The value weight
\(W_{v} \in R^{{d{model} \;* \;d{v}}}\)
Step 3: Generating Q, K, and V
To obtain the query (Q), key (K), and value (V) matrices, you perform matrix multiplications between the input sequence X and the corresponding weight matrices
These operations can be seen as projecting the input X into three different "spaces" or representations:
Query Matrix (Q): This represents what the current token is "looking for" or "asking about" from the other tokens.
Key Matrix (K): This represents the information that other tokens have, i.e., how relevant or important they are
Value Matrix (V): This contains the actual information or representation of each token that will be passed forward.
Step 4: Why Multiply by Weight Matrices?
The reason for multiplying the embedded input by weight matrices is to allow the model to learn different representations for querying, comparing, and retrieving information:
Wq learns how to map each input token into a query representation.
Wk learns how to map each token into a key representation.
Wv learns how to map each token into a value representation.
These projections allow the self-attention mechanism to focus on different aspects of the input tokens when calculating attention scores.
Example:
For simplicity, let’s assume we have a sequence of 3 tokens, each represented by a 4-dimensional embedding. Our input X could look like this:
Where x1,x2,x3x are the embedded vectors for each token. Now, we multiply this input matrix X by the learnable weight matrices: Q=X W_{q} K=X W_{k} V=X W_{v}
This generates the query, key, and value representations for each token, and these representations are then used to compute attention scores and retrieve relevant information.
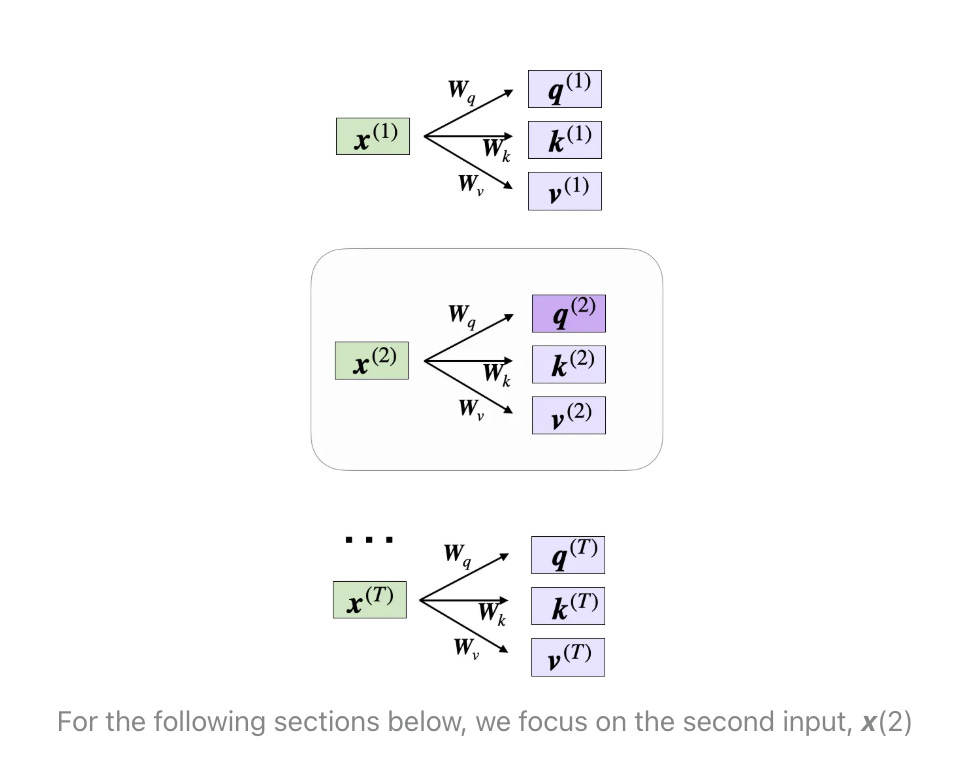
It needs to be noted that the query, key, value are generated for all input tokens as illustraed below.
Query sequence: q(i) = x(i)Wq for i in sequence 1 … T
Key sequence: k(i) = x(i)Wk for i in sequence 1 … T
Value sequence: v(i) = x(i)Wv for i in sequence 1 … T

Here, both q(i) and k(i) are vectors of dimension dk. The projection matrices Wq and Wk have a shape of d × dk , while Wv has the shape d × dv (It's important to note that d represents the size of each word vector, x.)
So, for the following code walkthrough, we will set dq = dk = 2 and use dv = 4, initializing the projection matrices as follows:
Computing the Unnormalized Attention Weights
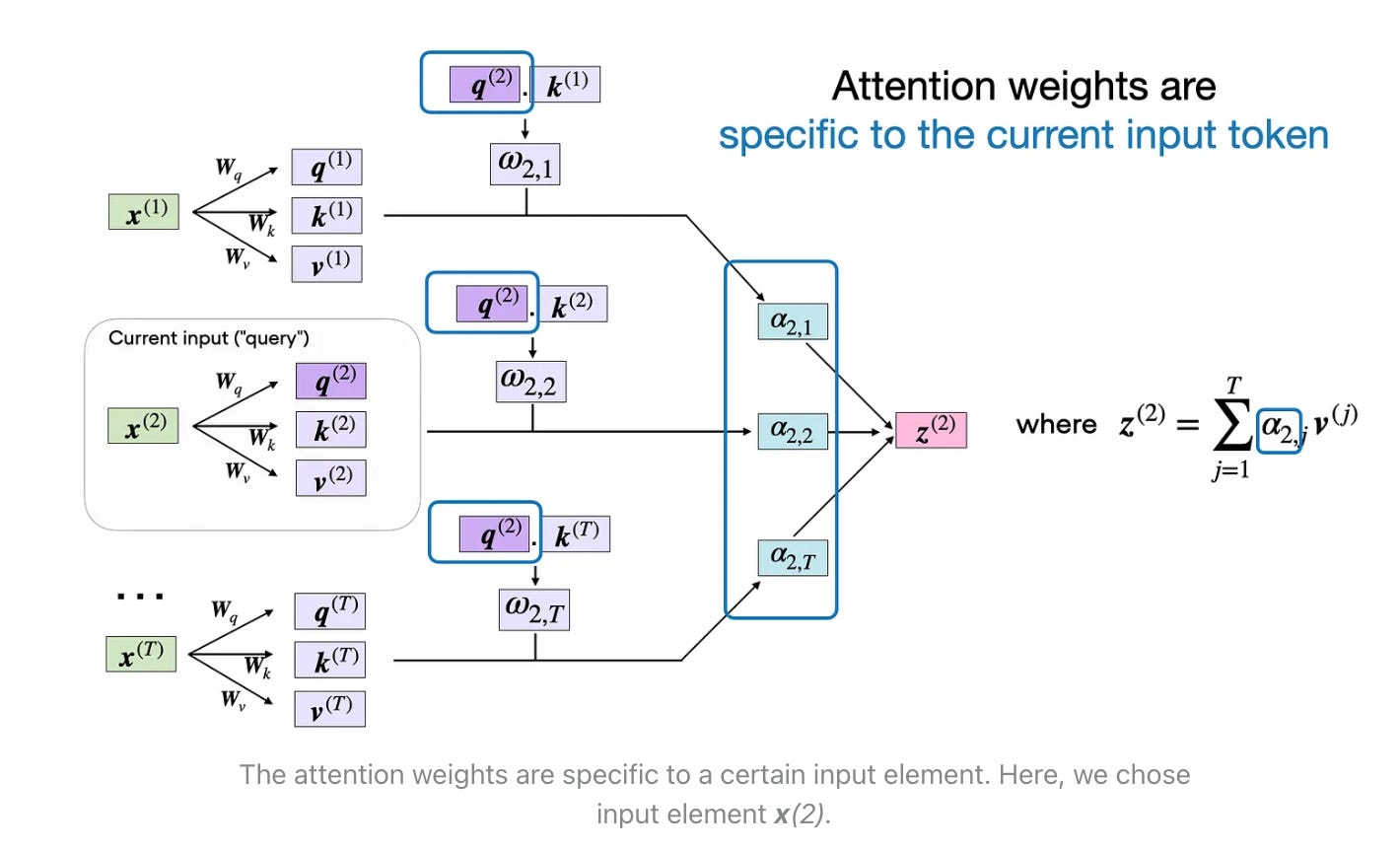
Now, let's suppose we are interested in computing the attention vector for the second input element -- the second input element acts as the query here: note that this computation is done for all the other inputs, we are just illustrating with this one.

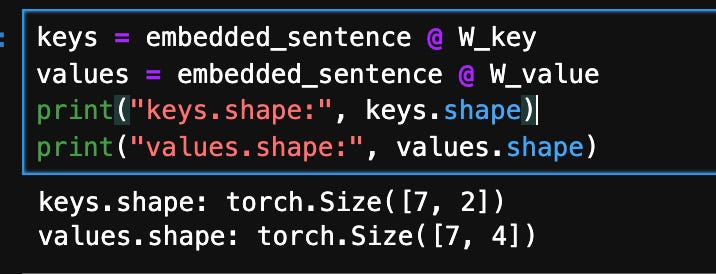
We can then generalize this to compute the remaining key, and value elements for all inputs as well, since we will need them in the next step when we compute the unnormalized attention weights later:
Symbol(@) is used for matrix multiplication (introduced in Python 3.5 as part of PEP 465). It is equivalent to the torch.matmul() function in PyTorch.
Now that we have all the required keys and values, we can proceed to the next step and compute the unnormalized attention weights ω (omega), which are illustrated in the figure below:
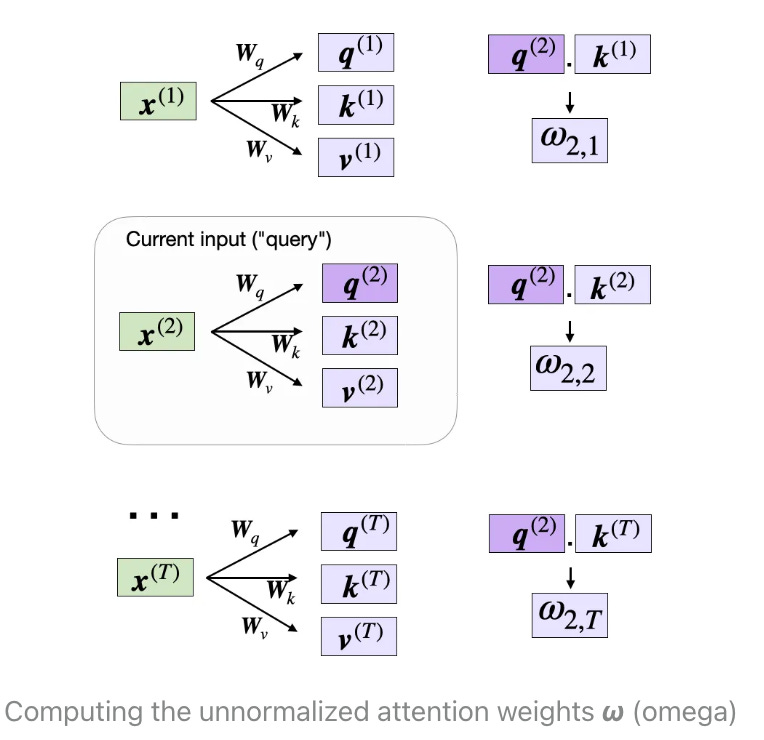
As illustrated in the figure above, we compute ωi,j as the dot product between the query and key sequences, ωi,j = q(i) k(j). eg ω2,2 = q(2) k(4)
For example, we can compute the unnormalized attention weight for the query and 5th input element (corresponding to index position 4) as follows:
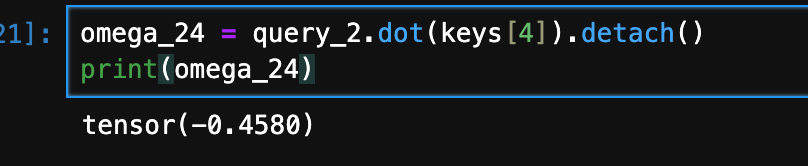
Since we will need those unnormalized attention weights ω to compute the actual attention weights later, let's compute the ω values for all input tokens as illustrated in the previous figure:

Computing the Attention Weights
The subsequent step in self-attention is to normalize the unnormalized attention weights, ω, to obtain the normalized attention weights, α (alpha), by applying the softmax function. Additionally, 1/√{dk} is used to scale ω before normalizing it through the softmax function, as shown below:

The scaling by dk ensures that the Euclidean length of the weight vectors will be approximately in the same magnitude. This helps prevent the attention weights from becoming too small or too large, which could lead to numerical instability or affect the model's ability to converge during training.
In code, we can implement the computation of the attention weights as follows:

Finally, the last step is to compute the context vector z(2), which is an attention-weighted version of our original query input x(2), including all the other input elements as its context via the attention weights:

Self-Attention
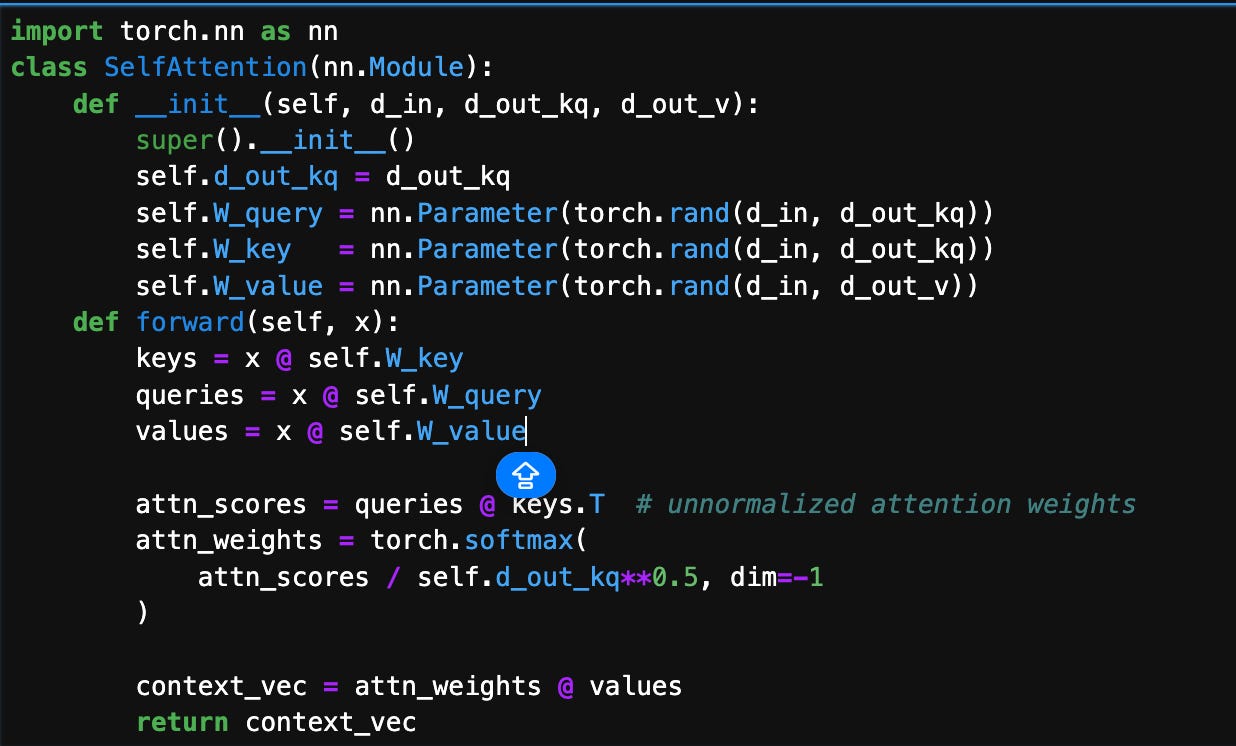
Now, to wrap up the code implementation of the self-attention mechanism in the previous sections above, we can summarize the previous code in a compact SelfAttention class:

I would end it here as it is becoming too lengthy, will complete on the next chapter of multi-headed attention in the next chapter of this post.
Thank you for reading and like the post.